
Cloud-optimized USGS time series data
Compressed formats, Zarr and Parquet scale much better for retrieving, reading, and storing USGS discharge time series data.
Intro
The scalability, flexibility, and configurabilty of the commercial cloud provide new and exciting possibilities for many applications including earth science research. As with many organizations, the US Geological Survey (USGS) is exploring the use and advantages of the cloud for performing their science. The full benefit of the cloud, however, can only be realized if the data that will be used is in a cloud-friendly format.
But what is a cloud-friendly format? Cloud providers offer different storage options and one of the most popular is object storage. Amazon Web Services’ (AWS) S3 and Google Clound’s Cloud Storage provide object storage. Object storage is non-hierarchical and with every object having a globally unique identifier. Cloud-friendly file formats take advantage of object storage by having chunked and compressed data stores which, in object storage, can be read and written in parallel.
In this blog post we’ll compare three formats for storing time series data: Zarr, Parquet, and CSV. Zarr (zarr.readthedocs.io ) and Parquet (parquet.apache.org ) are compressed, binary data formats that can also be chunked or partitioned. CSV will serve as a baseline comparison as a long-time standard format for time series data storage.
We are doing this comparision using time series data that are stored in and served from the USGS National Water Information System (NWIS). NWIS serves time series recorded at thousands observation locations throughout the US. These observations are of dozens of water science variables. The comparison will use discharge (or streamflow) data that were, for the most part, recorded at 15-minute intervals.
Comparison set up
There were two major comparisons. First we compared NWIS to Zarr for retrieval and formatting of time series for a subset of stations. Second we compared the read speeds and storage requirements between Zarr, Parquet, and CSV for the same subset of stations. We did these comparisons using a stock AWS EC2 t3a.large machine (8GB memory). The code we used to do these comparisons is here . Both comparisons were done for 1) a 10-day period and 2) a 40-year period.
Initial data gathering
For the first comparison, we first needed to gather the discharge data from all stations and write them to Zarr in an S3 bucket stored on the USGS’s virtual private cloud, Cloud-Hosting Solution (CHS). Altogether we gathered data from more than 12,000 stations across the continental US for a period of record of 1970-2019 using the NWIS web services (waterservices.usgs.gov/rest/IV-Service.html ).
Subset of basins
To do the comparison between the file formats we selected the Schuylkill River Basin, a sub-basin of the Delaware River Basin. Recently, the USGS initiated a program for the Next Generation Water Observation System (NGWOS ) in the Delaware River Basin. NGWOS will provide denser, less expensive, and more rapid water quality and quantity data than what is currently being offered by the USGS and the DRB is the first basin to pilot the new systems.
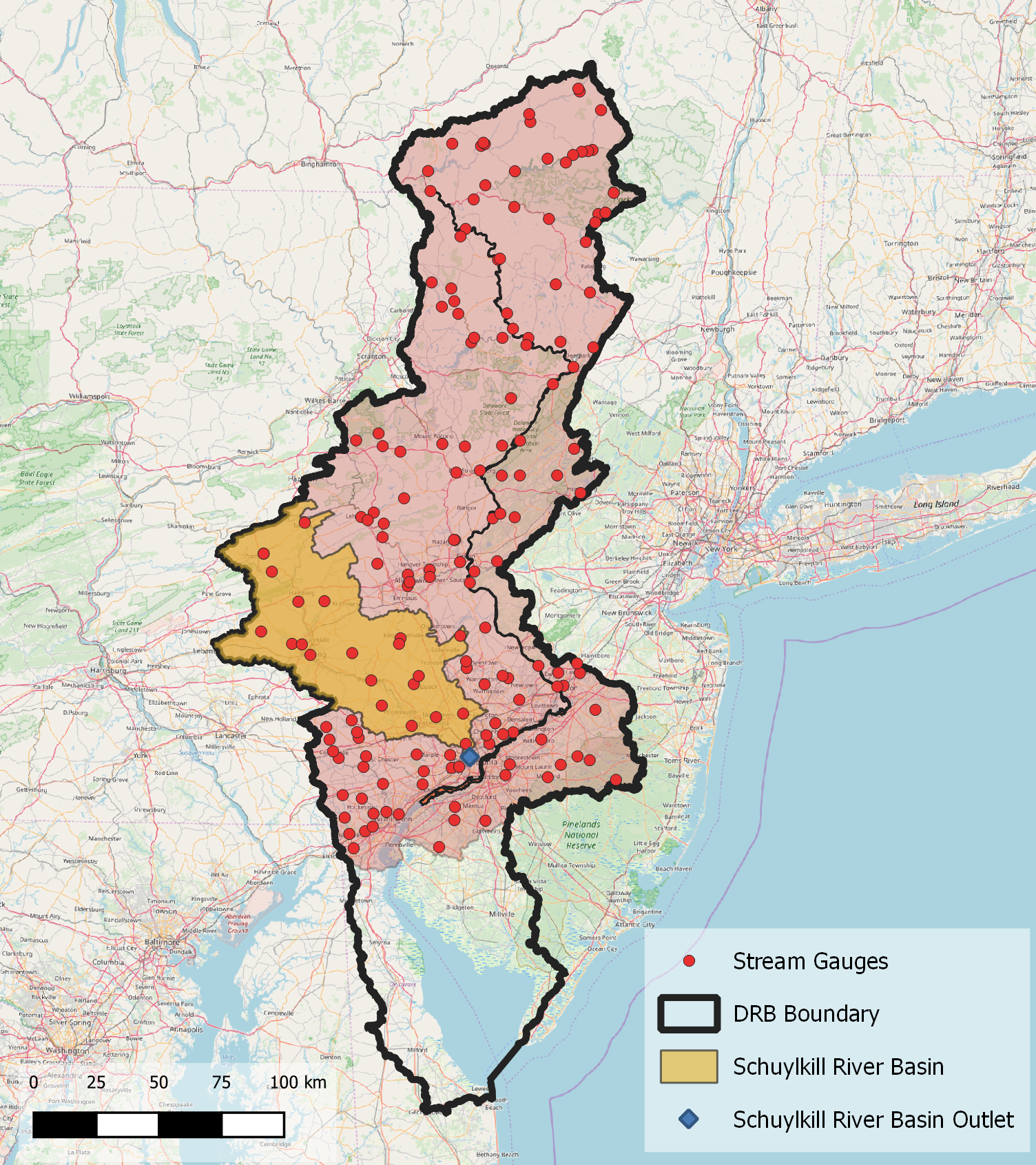
Delaware and Schuylkill River Basins
Comparison 1: Data retrieval and formatting (Zarr vs. NWIS web services)
We recorded the time it took to retrieve and format data using the NWIS web services and then from Zarr. We did the retrieval and formatting for one station (the overall outlet) and for all 23 stations in the sub-basin. We intended this comparison to answer the question: “If we have a bunch of sites in a data base (NWIS) or if we have a bunch of sites in a Zarr store, which one performs better at retrieving a relevant subset?”
For the formatting of the data, we converted the NWIS data into a Pandas DataFrame with a DateTime index. The formatting was necessary because NWIS webservices currently returns a plain text response (JSON) which then has to be parsed and read into memory before analysis. When the Zarr data is retrieved, it is already in an analysis-ready format as an Xarray dataset which can efficiently be operated on or converted to other formats such as a Pandas dataframe.
Comparison 2: Data read and storage (Zarr vs. Parquet vs CSV)
Once we retrieved the data subset, we wrote this subset to a new Zarr store, a Parquet file, and a CSV file. All of these files were written on the S3 bucket. We recorded the time it took to read from each, and the storage sizes of each.
Results
Comparison 1: Data retrieval and formatting
Table 1. Time in seconds to retrieve and format 10 days of data
| Zarr | NWIS web services | |
|---|---|---|
| Schuylkill outlet (sec) | 5.9 | 1.04 |
| all stations in Schuylkill basin (sec) | 6.1 | 19.7 |
Table 2. Time in seconds to retrieve and format 40 years of data
| Zarr | NWIS web services | |
|---|---|---|
| Schuylkill outlet (sec) | 5.8 | 29.8 |
| all stations in Schuylkill basin (sec) | 6.3 | 830 |
| all stations in Schuylkill basin retrieve (sec) | 401 |
Overall Zarr was much faster at retrieving data from a subset of observations compared to the NWIS web services and scaled very well. In fact, there was hardly any difference in retrieval time when increasing the volume of data requested. Consequently, the performance difference between Zarr and NWIS increased as the volume of data requested increased. NWIS was actually faster for a single station for the 10-day request. When we increased the single station to all 23 stations or the 10-day request to a 40-year request, Zarr was 3x and 4x faster, respectively. The largest difference, though, occurred when pulling the 40 years of data for all 23 stations: retrieving and formatting the data from Zarr was more than 127x faster compared to NWIS web services! And this difference was only for 23 stations! Imagine the difference if we wanted 123 stations (only about 1% of the total stations available).
The substantially better performance of the Zarr in S3 compared to NWIS is two-fold. First the Zarr data is located in the same AWS region as the EC2 machine. This is in contrast to the NWIS which has to transfer the data through the internet. Second, the Zarr data does not need to be formatted. About half of the 830 seconds to get the 40-year, 23-station NWIS data in a analysis-ready format was the actual formatting of the data.
Comparison 2: Data read and storage
Table 3. Read and storage for 10 days of data
| Zarr | Parquet | CSV | |
|---|---|---|---|
| read (sec) | 0.3 | 0.02 | 0.02 |
| storage (kB) | 51.3 | 40.8 | 124.1 |
Table 4. Read and storage for 40 years of data
| Zarr | Parquet | CSV | |
|---|---|---|---|
| read (sec) | 1.1 | 0.6 | 3.7 |
| storage (MB) | 33.5 | 15.4 | 110 |
Parquet was the best performing for read times and storage size for both the 10-day and 40-year datasets. Zarr was the slowest format for read for the 10-day dataset. The performance of the CSV format was comparable to Parquet with the 10-day dataset and even faster reading. However, CSV scaled very poorly with the 40-year dataset. This was especially true of the the read times which increased over 185x for CSV. In contrast, the maximum increase for either Zarr or Parquet between the 10-day and 40-year dataset was a 30x increase in the Parquet read time. CSV also required a considerably larger storage size (3x compared to Zarr for the 40-year dataset).
Discussion
Since Parquet performed the best in nearly all of the categories of Comparison 2, you may be wondering, “why didn’t you use Parquet to store all of the discharge data instead of Zarr?” The answer to that is flexibility. Zarr is a more flexible format than Parquet. Zarr allows for chunking along any dimension. Parquet is a columnar data format and allows for chunking only along one dimension. Additionally, Xarray’s interface to Zarr makes it very easy to append to a Zarr store. This was very handy when we were making all of the NWIS web service calls. Even though the connection was very reliable because it was on a cloud machine, there times where the connection was dropped whether it was on EC2 side or the NWIS side. Because we could append to Zarr, when the connection dropped we could just pick up from the last chunk of data we had written and keep going.
The results of Comparison 1 show great promise in making large-scale USGS data more readily accessible through cloud-friendly formats on cloud storage. My speculation is that cloud-accessible data one day may serve as a complement to or a complete replacement of traditional web services. Because the S3 bucket is in the CHS cloud, any USGS researcher that has CHS access will have access to the same dataset that we did the tests on. Although we did the analysis on stations in the Schuylkill River Basin, similar results should be able to be produced with any arbitrary subset of NWIS stations. This retrieval is possible without any type of web-service for subsetting the data. Since Zarr is chunked, object storage it is easily and efficiently subsettable with functionality built into the interfacing software package (i.e., Xarray in Python). Additionally, the data is read directly into a computation friendly in-memory format (i.e., an Xarray dataset) instead of plain text in an HTML response as is delivered by a web service.
Beside efficient access, a major benefit of storing the data in the S3 bucket in Zarr is the proximity to and propensity for scalable computing. Through the cloud, a computational cluster could be quickly scaled up to efficiently operate on the chunks of Zarr data. Cloud-hosted data and accompanying tools such as the Pangeo software stack will open up new possibilities for scientific research by USGS scientists and others enabling large-scale research.
Conclusion
The two big takeaways for me from this exercise were 1) time series data retrieval scales much much better with Zarr compared to using NWIS and 2) Parquet and Zarr scale much better in the reading and storage of time series compared CSV. These takeaways highlight the benefits of cloud-friendly storage formats when storing data on the cloud.
Categories:
Related Posts
Tutorial of dataRetrieval's newest features in R
November 26, 2025
This article will describe the R-package
dataRetrieval, which simplifies the process of finding and retrieving water from the U.S. Geological Survey (USGS) and other agencies. We have recently released a new version ofdataRetrievalto work with the modernized Water Data APIs . The new version ofdataRetrievalhas several benefits for new and existing users:Reproducible Data Science in R: Say the quiet part out loud with assertion tests
September 2, 2025

Overview
This blog post is part of the Reprodicuble data science in R series that works up from functional programming foundations through the use of the targets R package to create efficient, reproducible data workflows.
Duplicating Quarto elements with code templates to reduce copy and paste errors
May 20, 2025
Introduction

It is a common situation in data science and analysis: We want to create a series of figures, tables, or summary statistics for a set of data. Maybe we’re studying different species of irises or penguins or the current flow conditions for various streamgages (the example used below), and we want a different summary figure or table for each. One common approach is to write code for one set of the data, such as setting up the graphing parameters in a
ggplotdata visualization or calculating a series of statistics for a single species/streamgage. Then, once happy with that, copying and pasting the code for each entity, modifying the code slightly for each iteration.Formatting guidance for USGS Samples Data Tables
May 6, 2025
Recently, changes were made to the delivery format of USGS samples data (learn more here ). In this blog, we describe the impact to users and show an example of how to use R to convert WQX-formatted water quality results data to a tabular, or “wide” view.
Reproducible Data Science in R: Flexible functions using tidy evaluation
December 17, 2024

Overview
This blog post is part of a series that works up from functional programming foundations through the use of the targets R package to create efficient, reproducible data workflows.