
Accessing LOCA Downscaling Via OPeNDAP and the Geo Data Portal with R.
Introduction
In this example, we will use the R programming language to access LOCA data via the OPeNDAP web service interface using the ncdf4 package then use the geoknife package to access LOCA data using the Geo Data Portal as a geoprocessing service. More examples like this can be found at the Geo Data Portal wiki.
A number of other packages are required for this example. They include: tidyr for preparing data to plot; ggplot2 to create the plots; grid and gridExtra to layout multiple plots in the same figure; jsonlite and leaflet to create the simple map of a polygon; and chron, climates, and PCICt to calculate derived climate indices. They are all available from CRAN except climates which can be installed from github.
About LOCA
This new, feely available, statistically downscaled dataset is summarized in depth at the U.C. San Diego home web page: Summary of Projections and Additional Documentation
From the Metadata: LOCA is a statistical downscaling technique that uses past history to add improved fine-scale detail to global climate models. We have used LOCA to downscale 32 global climate models from the CMIP5 archive at a 1/16th degree spatial resolution, covering North America from central Mexico through Southern Canada. The historical period is 1950-2005, and there are two future scenarios available: RCP 4.5 and RCP 8.5 over the period 2006-2100 (although some models stop in 2099). The variables currently available are daily minimum and maximum temperature, and daily precipitation. For more information visit: http://loca.ucsd.edu/ The LOCA data is available due to generous support from the following agencies: The California Energy Commission (CEC), USACE Climate Preparedness and Resilience Program and US Bureau of Reclamation, US Department of Interior/USGS via the Southwest Climate Science Center, NOAA RISA program through the California Nevada Applications Program (CNAP), NASA through the NASA Earth Exchange and Advanced Supercomputing (NAS) Division Reference: Pierce, D. W., D. R. Cayan, and B. L. Thrasher, 2014: Statistical downscaling using Localized Constructed Analogs (LOCA). Journal of Hydrometeorology, volume 15, page 2558-2585.
OPeNDAP Web Service Data Access
We’ll use the LOCA Future dataset available from the cida.usgs.gov thredds server. The OPeNDAP service can be seen here. and the OPeNDAP base url that we will use with ncdf4 is: http://cida.usgs.gov/thredds/dodsC/loca_future. In the code below, we load the OPeNDAP data source and look at some details about it.
NOTE: The code using ncdf4 below will only work on mac/linux installations of ncdf4. Direct OPeNDAP access to datasets is not supported in the Windows version of ncdf4.
library(ncdf4)
loca_nc <- nc_open('http://cida.usgs.gov/thredds/dodsC/loca_future')
loca_globals <- ncatt_get(loca_nc, varid = 0)
names(loca_globals) # Available global attributes.
## [1] "history" "creation_date" "Conventions"
## [4] "title" "acknowledgment" "Metadata_Conventions"
## [7] "summary" "keywords" "id"
## [10] "naming_authority" "cdm_data_type" "publisher_name"
## [13] "publisher_url" "creator_name" "creator_email"
## [16] "time_coverage_start" "time_coverage_end" "date_modified"
## [19] "date_issued" "project" "publisher_email"
## [22] "geospatial_lat_min" "geospatial_lat_max" "geospatial_lon_min"
## [25] "geospatial_lon_max" "license"
names(loca_nc) # top level names of the ncdf4 object.
## [1] "filename" "writable" "id" "safemode" "format"
## [6] "is_GMT" "groups" "fqgn2Rindex" "ndims" "natts"
## [11] "dim" "unlimdimid" "nvars" "var"
names(loca_nc$dim) # Dimensions of the ncdf4 object.
## [1] "bnds" "lat" "lon" "time"
loca_nc$nvars # How many variables are available from the ncdf4 object.
## [1] 171
From this, we can see the global variables that are available for the dataset as well as the ncdf4 object’s basic structure. Notice that the dataset has 171 variables!
Point-based time series data
For this example, we’ll look at the dataset in the Colorado Platte Drainage Basin climate division which includes Denver and North Central Colorado. For the examples that use a point, well use 40.2 degrees north latitude and 105 degrees west longitude, along I25 between Denver and Fort Collins.
Get time series data for a single cell.
First, let’s pull down a time series from our point of interest using ncdf4. To do this, we need to determine which lat/lon index we are interested in then access a variable of data at that index position.
lat_poi <- 40.2
lon_poi <- 360 - 105 # Note LOCA uses 0 - 360 so -105 is 255 degrees.
lat_index <- which.min(abs(lat_poi-loca_nc$dim$lat$vals))
lon_index <- which.min(abs(lon_poi-loca_nc$dim$lon$vals))
paste('lat',loca_nc$dim$lat$vals[lat_index],'lon',loca_nc$dim$lon$vals[lon_index])
## [1] "lat 40.21875 lon 254.96875"
names(loca_nc$var)[1:9]
## [1] "lat_bnds" "lon_bnds"
## [3] "time_bnds" "pr_CCSM4_r6i1p1_rcp45"
## [5] "tasmax_CCSM4_r6i1p1_rcp45" "tasmin_CCSM4_r6i1p1_rcp45"
## [7] "pr_CCSM4_r6i1p1_rcp85" "tasmax_CCSM4_r6i1p1_rcp85"
## [9] "tasmin_CCSM4_r6i1p1_rcp85"
start.time <- Sys.time()
test_var<-ncvar_get(nc = loca_nc,
varid = names(loca_nc$var)[5],
start = c(lon_index,lat_index,1),
count = c(1,1,-1))
Sys.time() - start.time # See how long this takes.
## Time difference of 1.653601 mins
Time series plot of two scenarios.
In the code above, we requested the fifth variable, or tasmax_CCSM4_r6i1p1_rcp45. Let’s request a second variable and see how rcp45 compares to rcp85. For this example, we’ll need three additional packages: chron to deal with the NetCDF time index conversion, tidyr to get data ready to plot with the gather function, and ggplot2 to create a plot of the data.
library(chron)
library(tidyr)
library(ggplot2)
test_var2<-ncvar_get(nc = loca_nc,
varid = names(loca_nc$var)[8],
start = c(lon_index,lat_index,1),
count = c(1,1,-1))
plot_dates<-as.POSIXct(chron(loca_nc$dim$time$vals,
origin=c(month=1, day=1, year=1900)))
pData<-gather_(data = data.frame(dates=plot_dates, rcp45=test_var, rcp85=test_var2),
key_col = "Pathway", value_col = "data", gather_cols = c("rcp45","rcp85"))
ggplot(pData,aes(x=dates,y=data,colour=Pathway,group=Pathway)) + geom_point(alpha=1/15) +
geom_smooth() + ylab('Daily Maximum Temperature (degrees C)') + xlab('Year') +
ggtitle(paste0('Daily Maximum Temperature from variables:\n',
names(loca_nc$var)[5],', ',names(loca_nc$var)[8])) +
theme(plot.title = element_text(face="bold"))
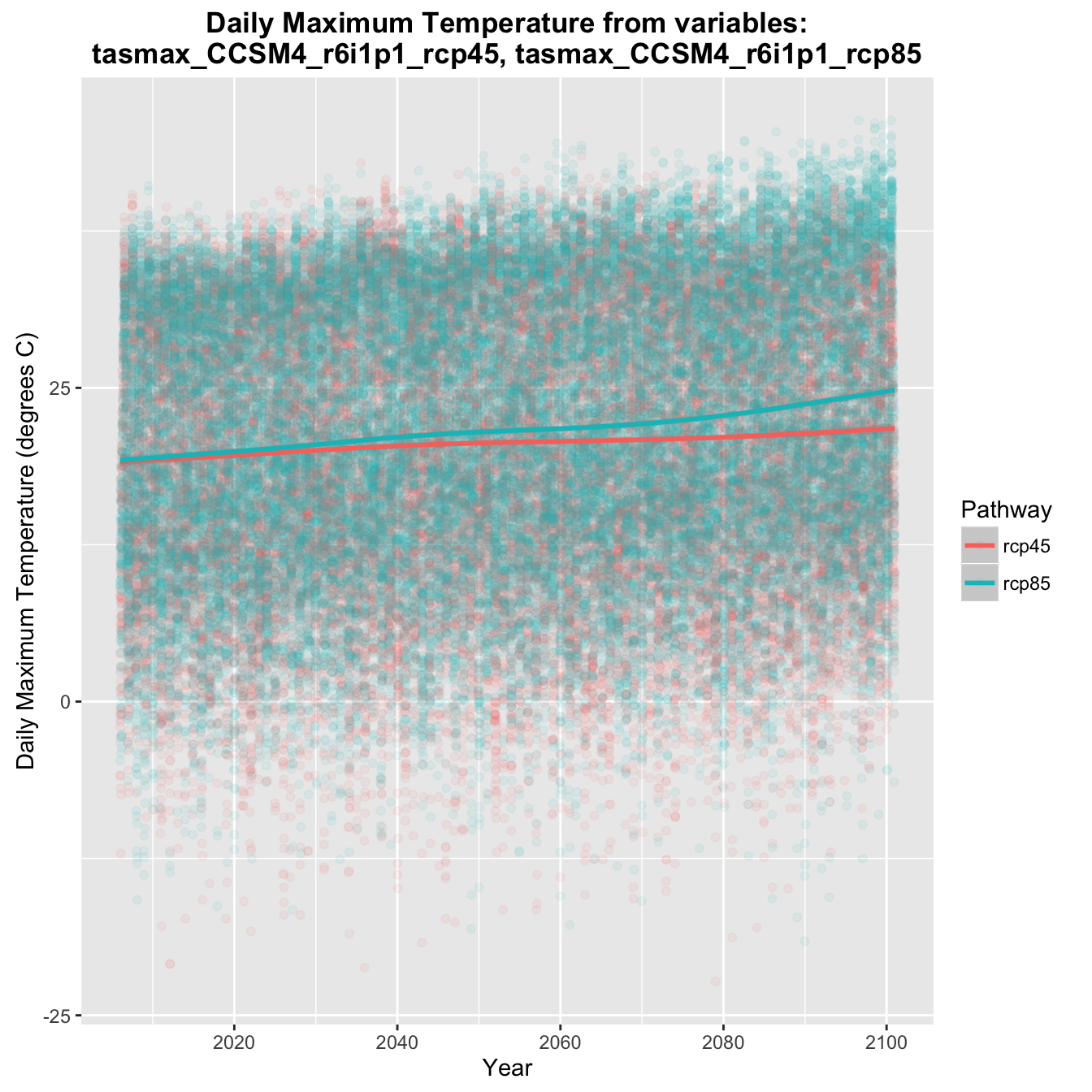
Graph of projected daily maximum temperature.
Areal average time series data access with the Geo Data Portal
Using the method shown above, you can access any variable at any lat/lon location for your application. Next, we’ll look at how to get areal statistics of the data for the Platte Drainage Basin climate division polygon shown above.
For this, we’ll need the package geoknife. In the code below, we setup the webgeom and webdata objects called stencil and fabric respectively. Then we make a request for one timestep to find out the SUM of the cell weights and the total COUNT of cells in the area weighted grid statistics calculation that the Geo Data Portal will perform at the request of geoknife. This tells us the fractional number of grid cells considered in the calculation as well as the total number of cells that will be considered for each time step.
library(geoknife)
stencil <- webgeom()
# query(stencil,'geoms') # Uncomment to see list of available geoms.
geom(stencil) <- 'sample:CONUS_Climate_Divisions'
# query(stencil, 'attributes') # Uncomment to see list of available attributes.
attribute(stencil) <- 'NAME'
# query(stencil, 'values') # Uncomment to see list of available attribute values.
values(stencil) <- 'PLATTE DRAINAGE BASIN'
fabric <- webdata(url='http://cida.usgs.gov/thredds/dodsC/loca_future')
varList<-query(fabric,'variables')
variables(fabric) <- "pr_CCSM4_r6i1p1_rcp45"
# query(fabric,'times') # Uncomment to see start and end dates.
times(fabric) <- c('2006-01-01', '2006-01-01')
knife <- webprocess(STATISTICS = c("SUM","COUNT"), wait = TRUE)
job_onestep <- geoknife(stencil, fabric, knife)
result(job_onestep)
## DateTime PLATTE DRAINAGE BASIN variable
## 1 2006-01-01 12:00:00 1465.039 pr_CCSM4_r6i1p1_rcp45
## 2 2006-01-01 12:00:00 1616.000 pr_CCSM4_r6i1p1_rcp45
## statistic
## 1 SUM
## 2 COUNT
Areal intersection calculation summary
This result shows that the SUM and COUNT are 1465.039 and 1616 respectively. This tells us that of the 1616 grid cells that partially overalap the Platte Drainage Basin polygon, the sum of cell weights in the area weighted grid statistics calculation is 1465.039. The Platte Drainage Basin climate division is about 52,200 square kilometers and the LOCA grid cells are roughly 36 square kilometers (1/16th degree). Given this, we would expect about 1450 grid cells in the Platte Drainage Basin polygon which compares will with the Geo Data Portal’s 1465.
Process time and request size analysis
Next, we’ll look at the time it might take to process this data with the Geo Data Portal. We’ll use the geoknife setup from above, but the default knife settings rather than those used above to get the SUM and COUNT. First we’ll get a single time step, then a year of data. Then we can figure out how long the spatial interstection step as well as each time step should take.
times(fabric) <- c('2006-01-01', '2006-01-01')
start.time <- Sys.time()
job_onestep <- geoknife(stencil, fabric, wait = TRUE)
time_one_step <- Sys.time() - start.time
times(fabric) <- c('2006-01-01', '2007-01-01')
start.time <- Sys.time()
job_oneyear <- geoknife(stencil, fabric, wait=TRUE)
time_one_year <- Sys.time() - start.time
time_per_step <- (time_one_year - time_one_step) / 364
steps_per_var <- 365 * (2100-2006)
time_per_var <- time_per_step * steps_per_var
time_per_int <- time_one_step - time_per_step
cat('Precip time is about',as.numeric(time_per_var,units="hours"), 'hours per variable. \nTime for spatial intersection is about',as.numeric(time_per_int), 'seconds.')
## Precip time is about 0.4170167 hours per variable.
## Time for spatial intersection is about 6.68374 seconds.
This result shows about how long we can expect each full variable to take to process and how much of that process is made up by the spatial intersection calculations. As can be seen, the spatial intersection is insignificant compared to the time series data processing, which means running one variable at a time should be ok.
In the case that the spatial intersection takes a lot of time and the data processing is quick, we could run many variables at a time to limit the number of spatial intersections that are performed. In this case, we can just run a single variable per request to geoknife and the Geo Data Portal.
GDP run to get all the data.
Now, lets run the GDP for the whole loca dataset. This will be 168 variables with each variable taking something like a half hour depending on server load. Assuming 30 minutes per variable, that is 84 hours! That may seem like a very long time, but considering that each variable is 34310 time steps, that is a throughput of about 19 time steps per second.
The code below is designed to keep retrying until the processing result for each has been downloaded successfully. For this demonstration, the processing has been completed and all the files are available in the working directory of the script. NOTE: This is designed to make one request at a time. Please don’t make concurrent requests to the GDP, it tends to be slower than executing them in serial.
times(fabric) <- c('2006-01-01', '2101-01-01')
ran_one<-TRUE
while(ran_one){
ran_one<-FALSE
for(var_to_get in varList) {
# print(var_to_get) # Uncomment for status
if(!file.exists(paste0('loca_demo/',var_to_get,'.csv'))) {
variables(fabric) <- var_to_get
job <- try(geoknife(stencil, fabric, wait=TRUE))
try(download(job,paste0('loca_demo/',var_to_get,'.csv')))
ran_one<-TRUE
}
}
}
loca_data_platte<-data.frame(dates=parseTimeseries(paste0('loca_demo/',varList[1],'.csv'),delim=',')$DateTime)
for(var_to_parse in varList) {
loca_data_platte[var_to_parse] <- parseTimeseries(paste0('loca_demo/',var_to_parse,'.csv'), delim=',')[2]
}
Derivative calculations
Now that we have all the data downloaded and it has been parsed into a list we can work with, we can do something interesting with it. The code below shows an example that uses the climates package, available on github to generate some annual indices of the daily data we accessed. For this example, we’ll look at all the data and 5 derived quantities.
Plot setup
Now we have a data in a structure that we can use to create some plots. First, we define a function from the ggplot2 wiki that allows multiple plots to share a legend.
Summary Plots
Now we can create a set of plot configuration options and a set of comparitive plots looking at the RCP45 (aggressive emmisions reduction) and RCP85 (business as usual).
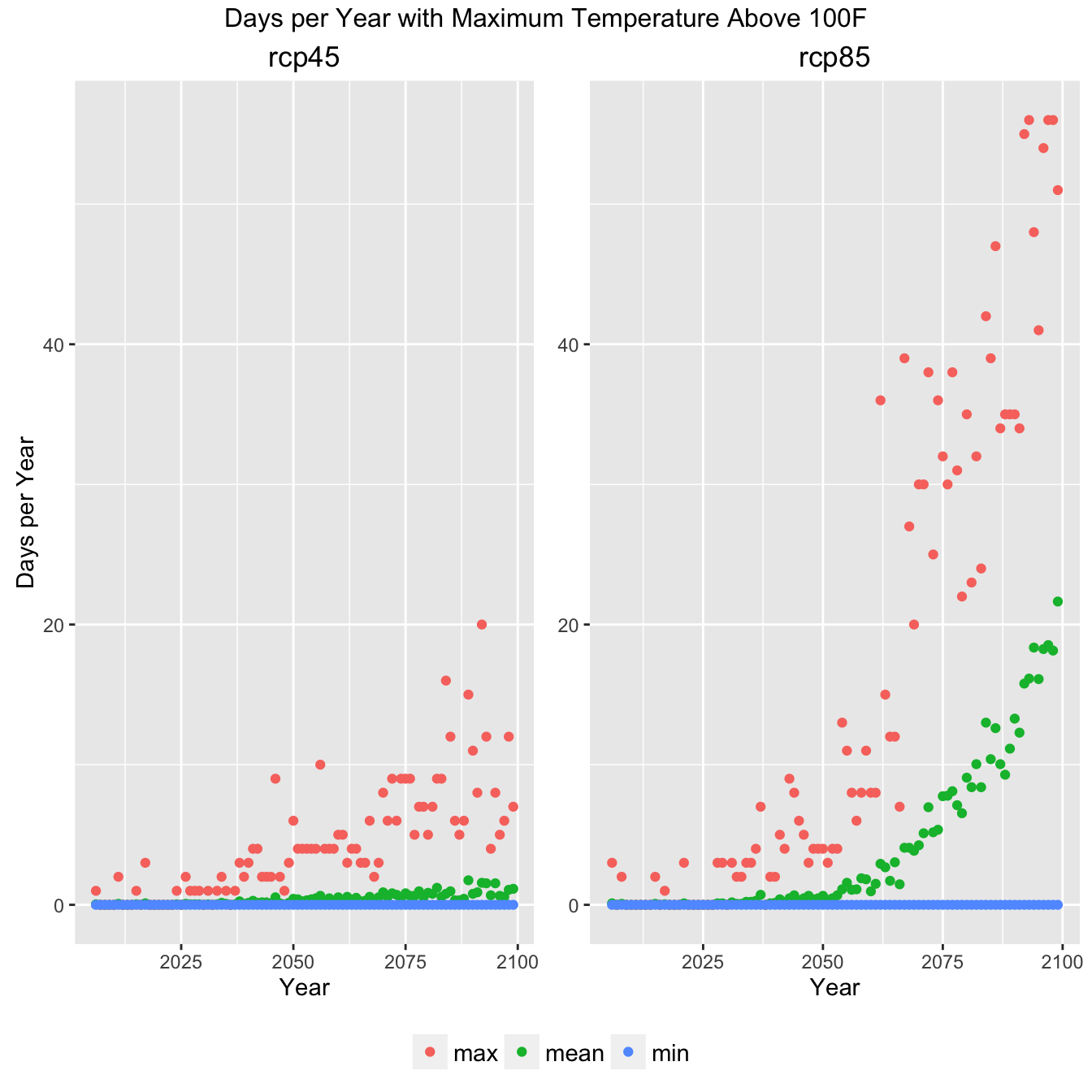
Climate Indicator Summary Graph
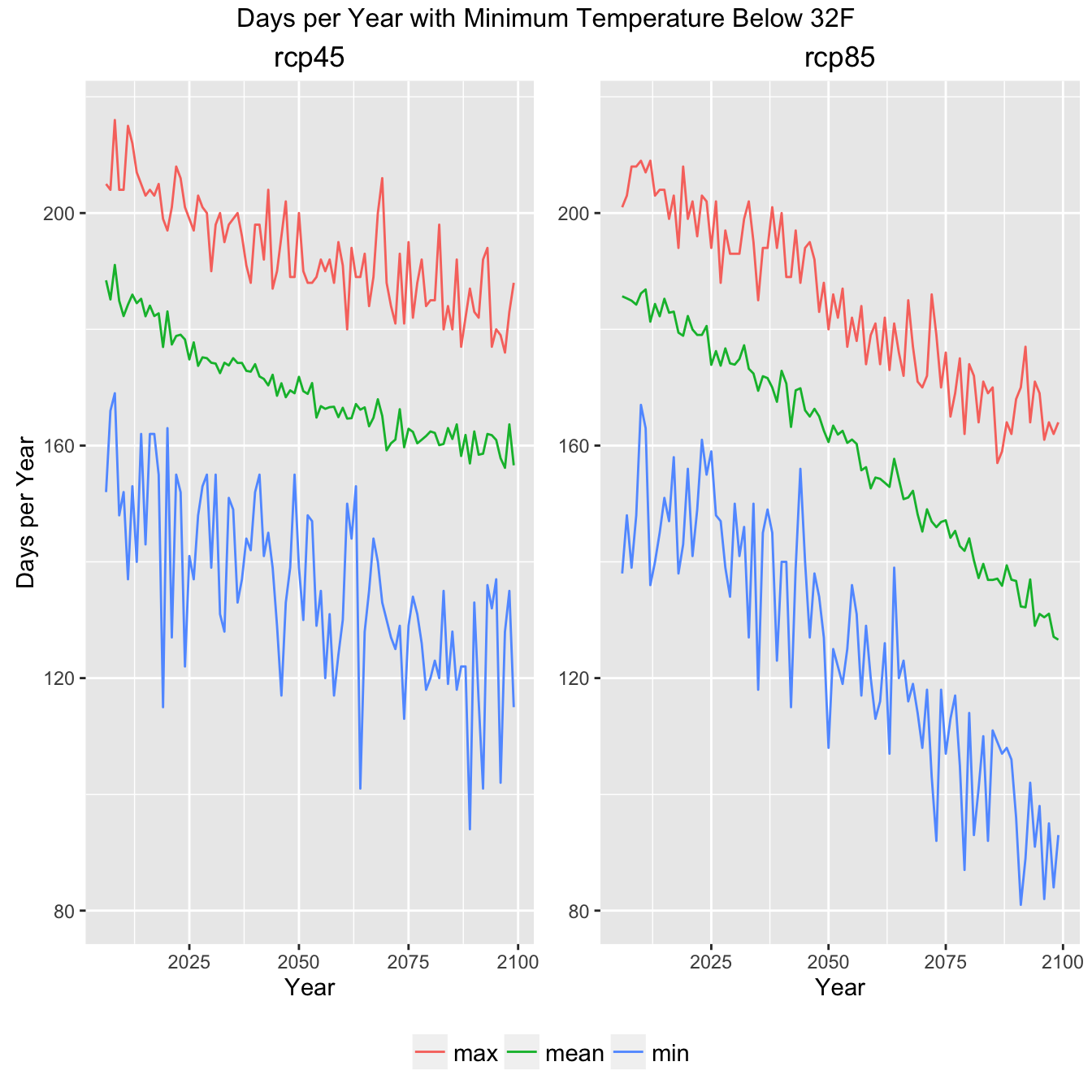
Climate Indicator Summary Graph
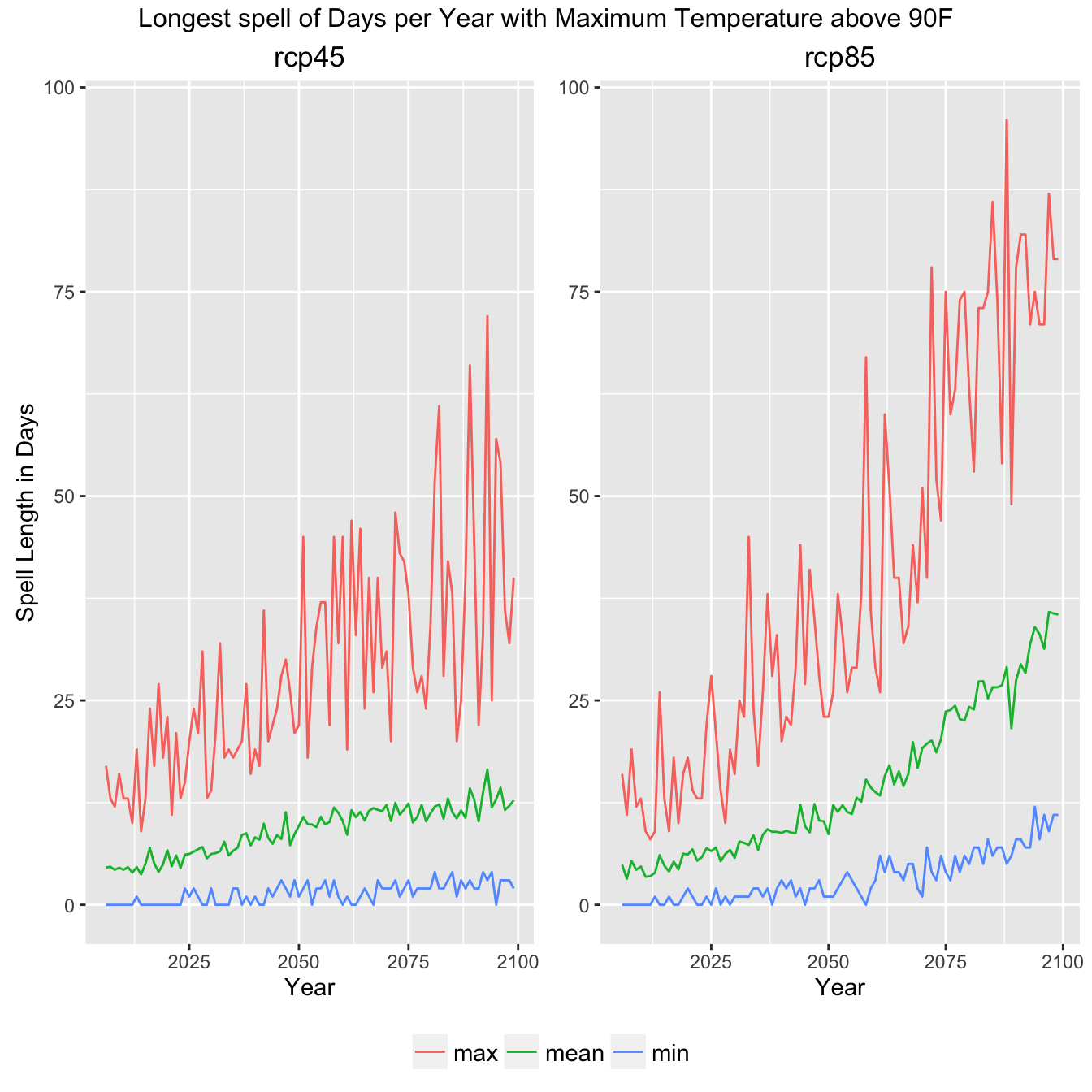
Climate Indicator Summary Graph
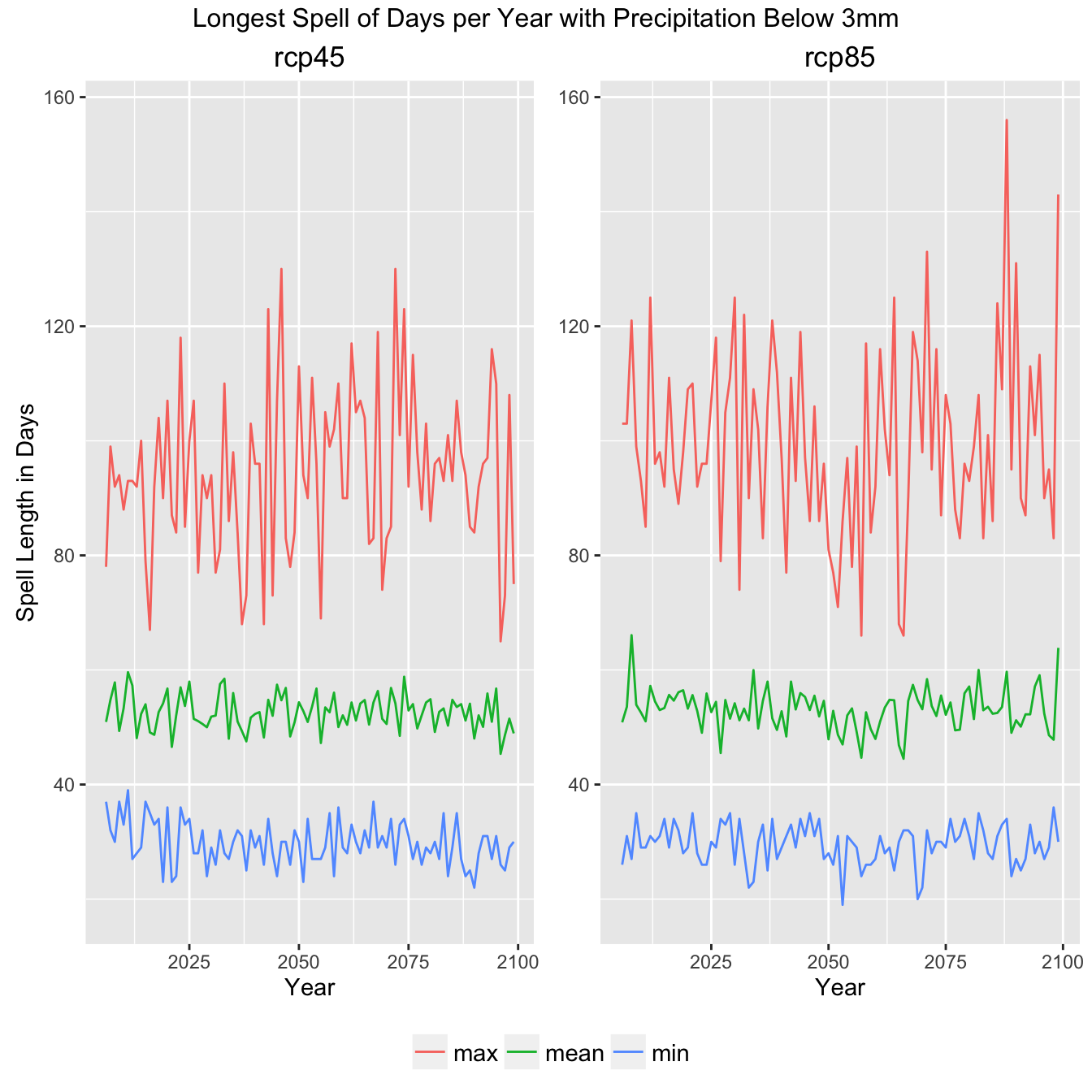
Climate Indicator Summary Graph
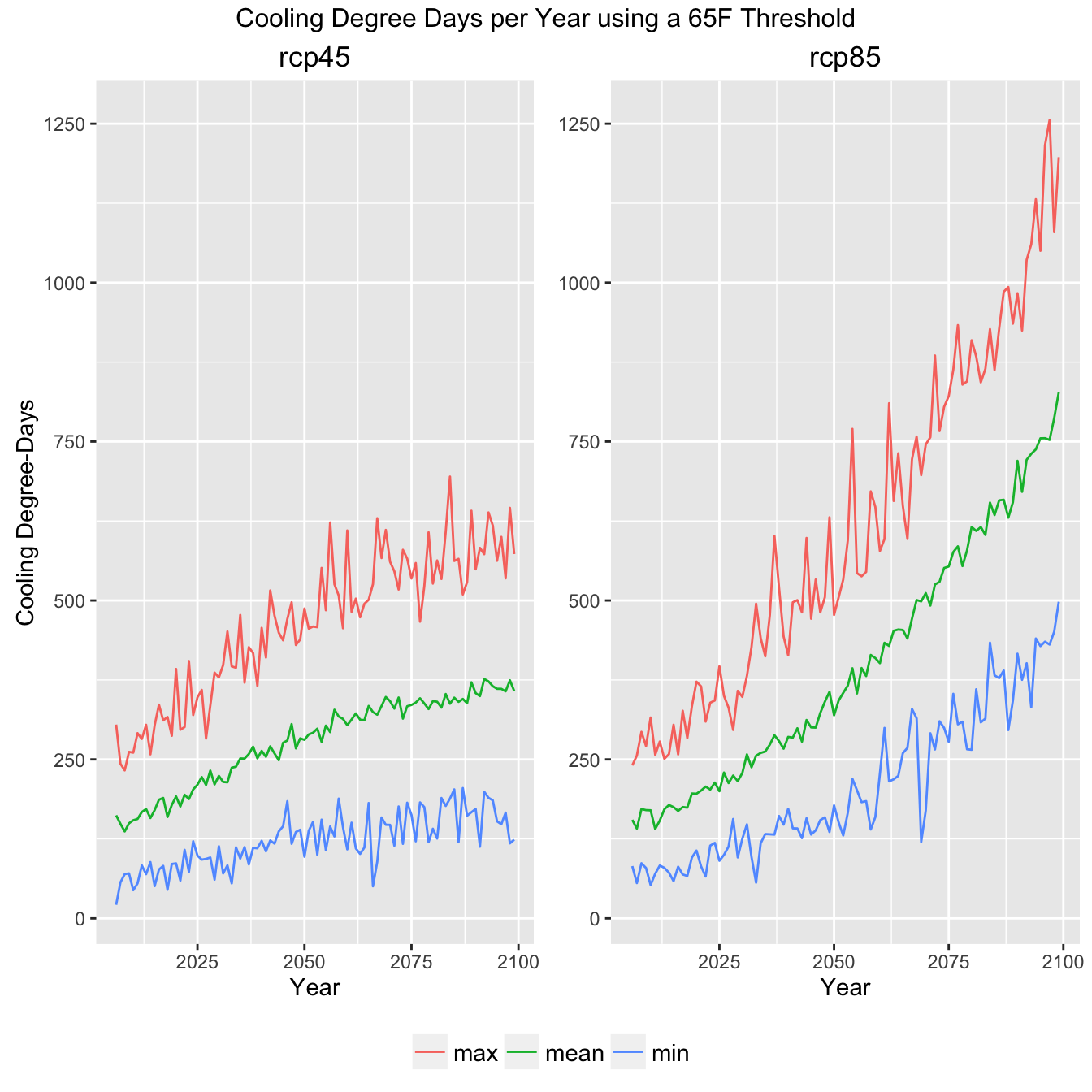
Climate Indicator Summary Graph
All GCM Plots
Finally, to give an impression of how much data this example actually pulled in, here are the same plots with all the GCMs shown rather then the ensemble mean, min, and max.
for(thresh in names(plot_setup)) {
plot_setup[[thresh]]$plotAllrcp45 <- plot_setup[[thresh]]$plotAllrcp45
plot_setup[[thresh]]$plotAllrcp85 <- plot_setup[[thresh]]$plotAllrcp85 +
theme(axis.title.y=element_blank())
grid_arrange_shared_legend(plot_setup[[thresh]]$plotAllrcp45,
plot_setup[[thresh]]$plotAllrcp85,
ncol=2, top=plot_setup[[thresh]]$title,
legend.text=element_text(size = 6))
}
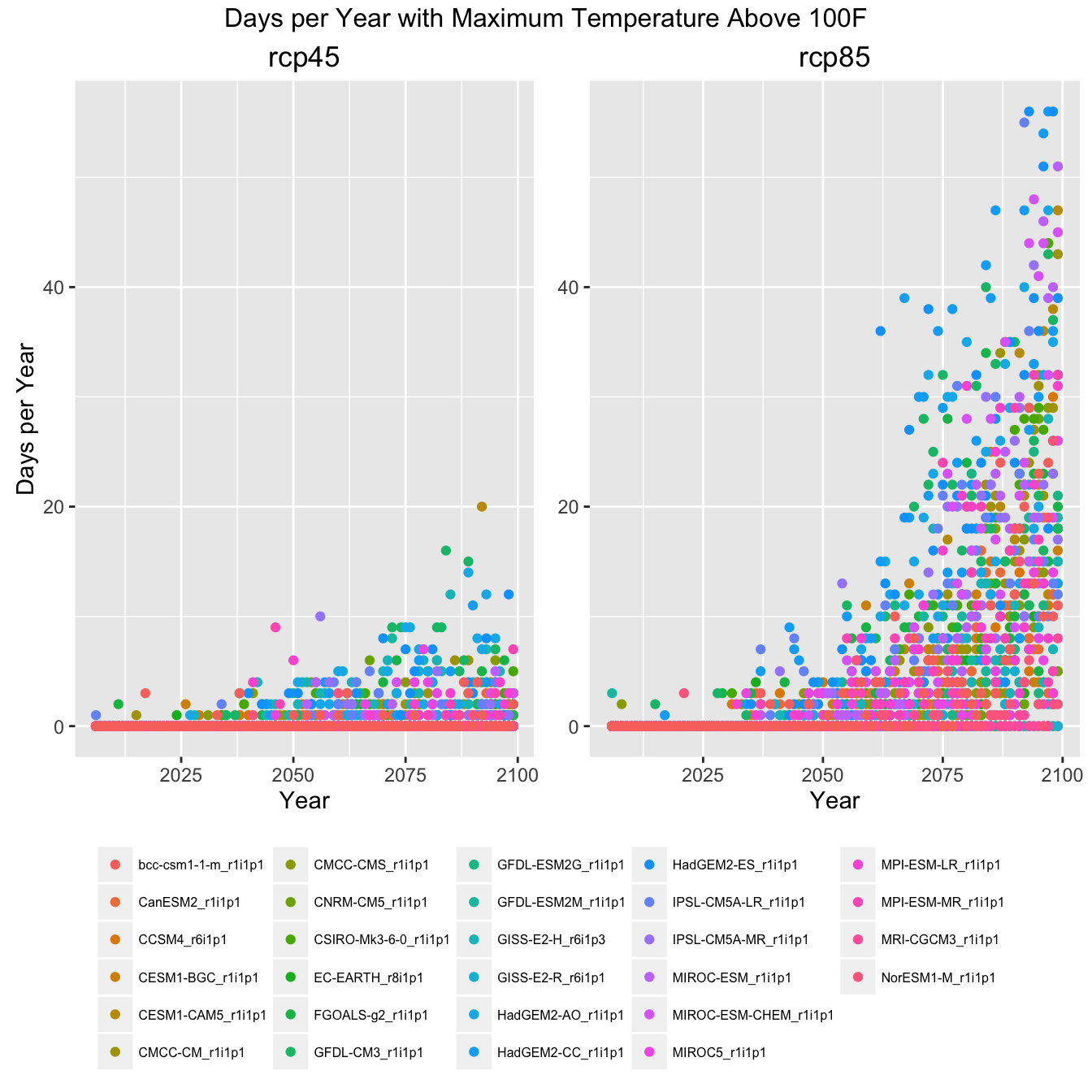
Climate Indicator Graph of All GCMs
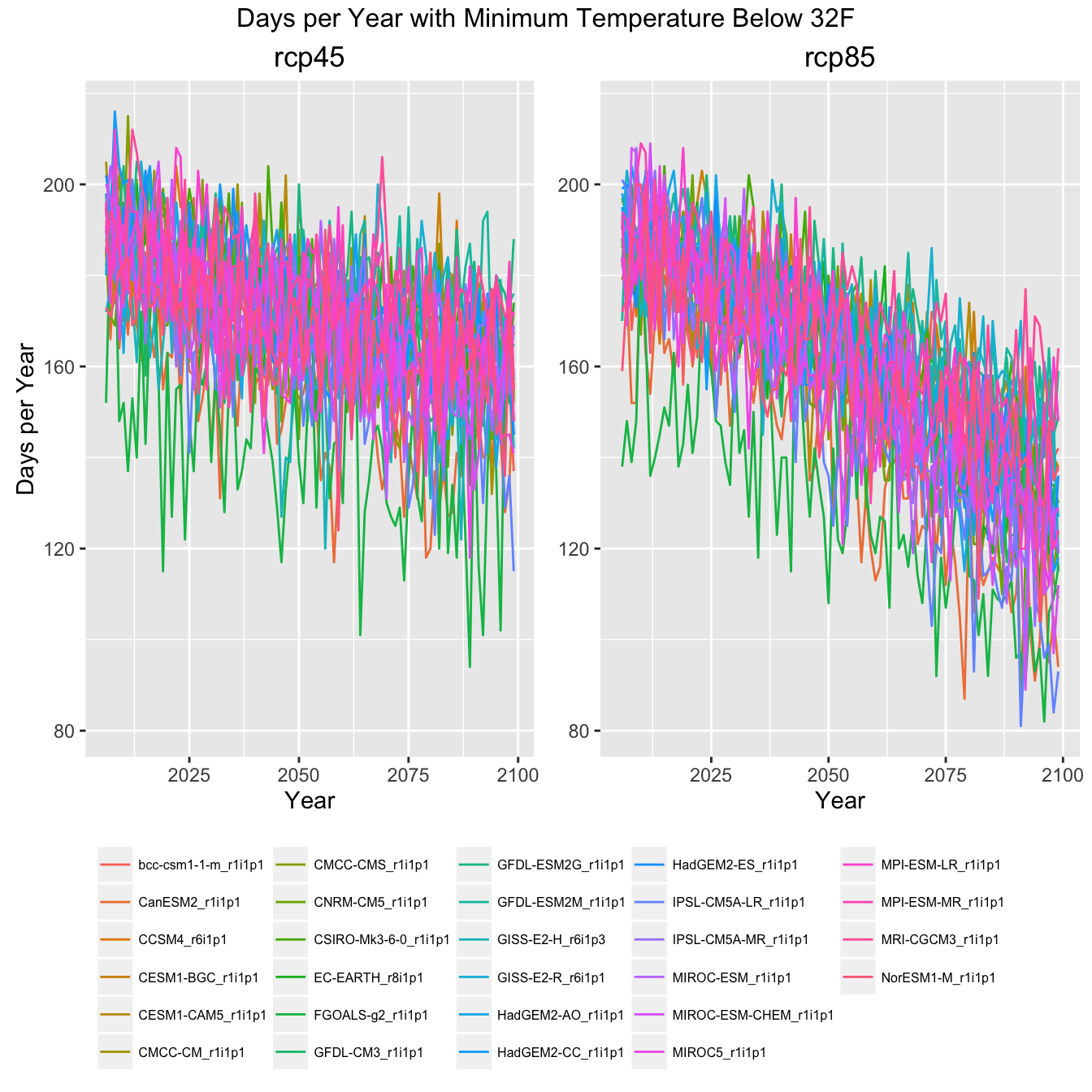
Climate Indicator Graph of All GCMs
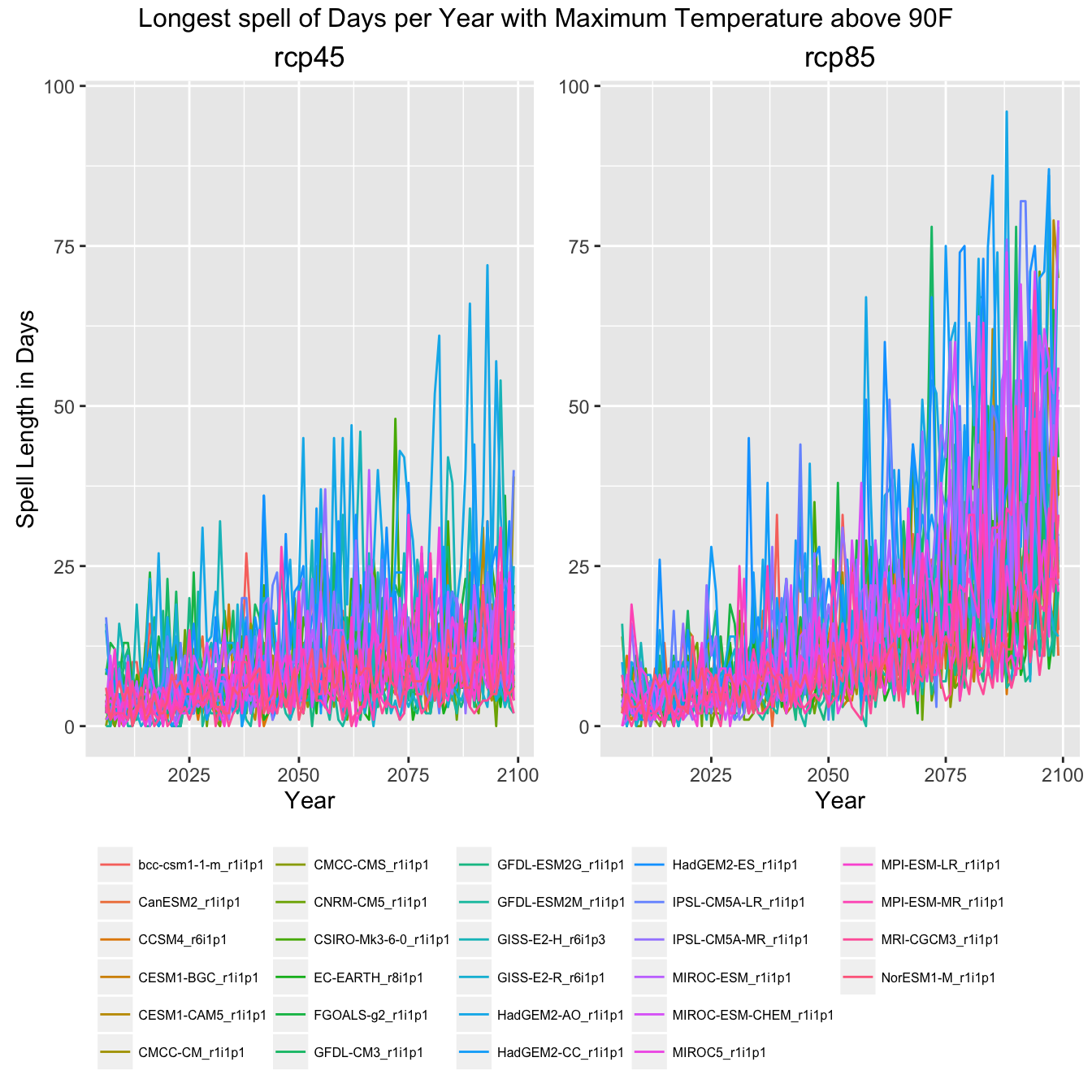
Climate Indicator Graph of All GCMs
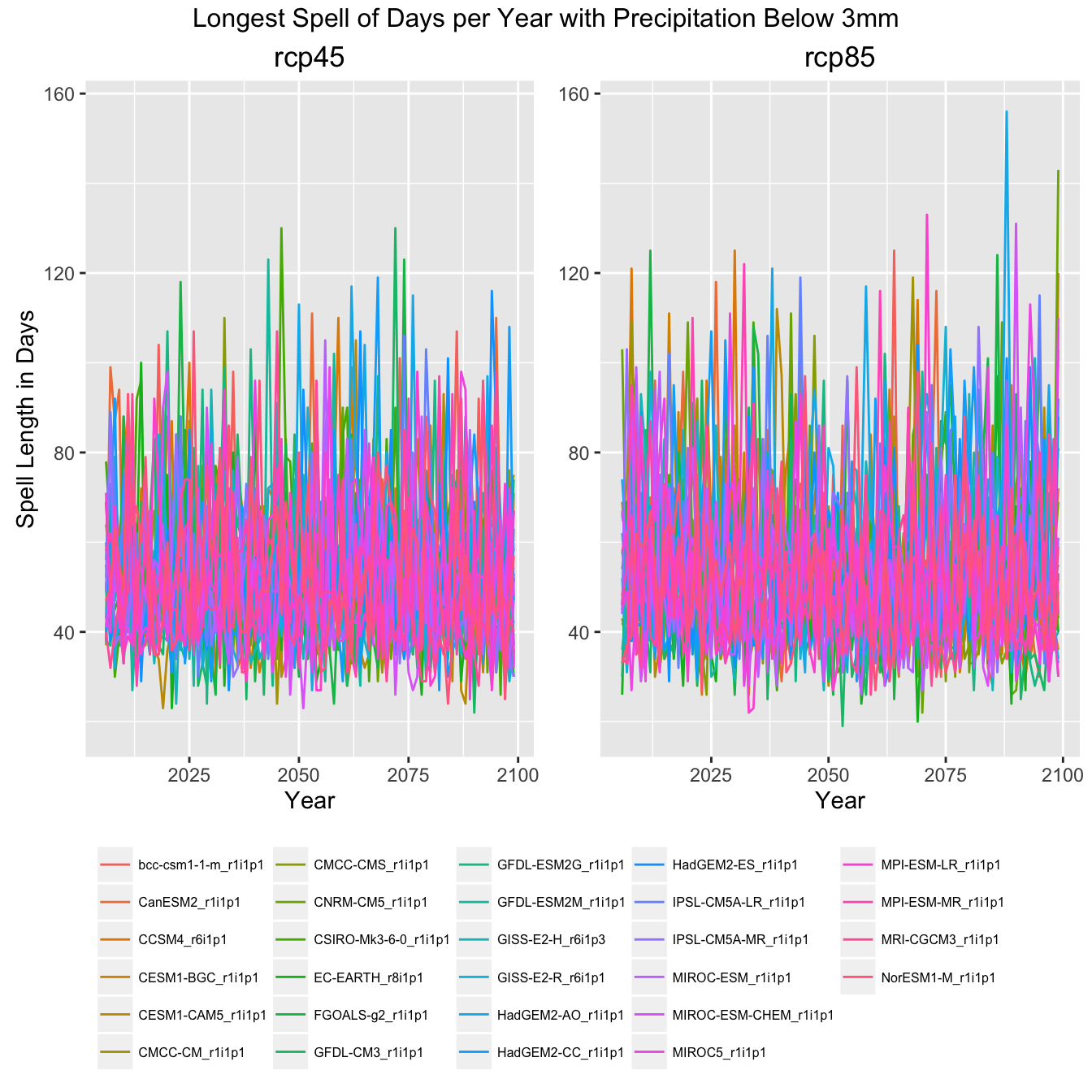
Climate Indicator Graph of All GCMs
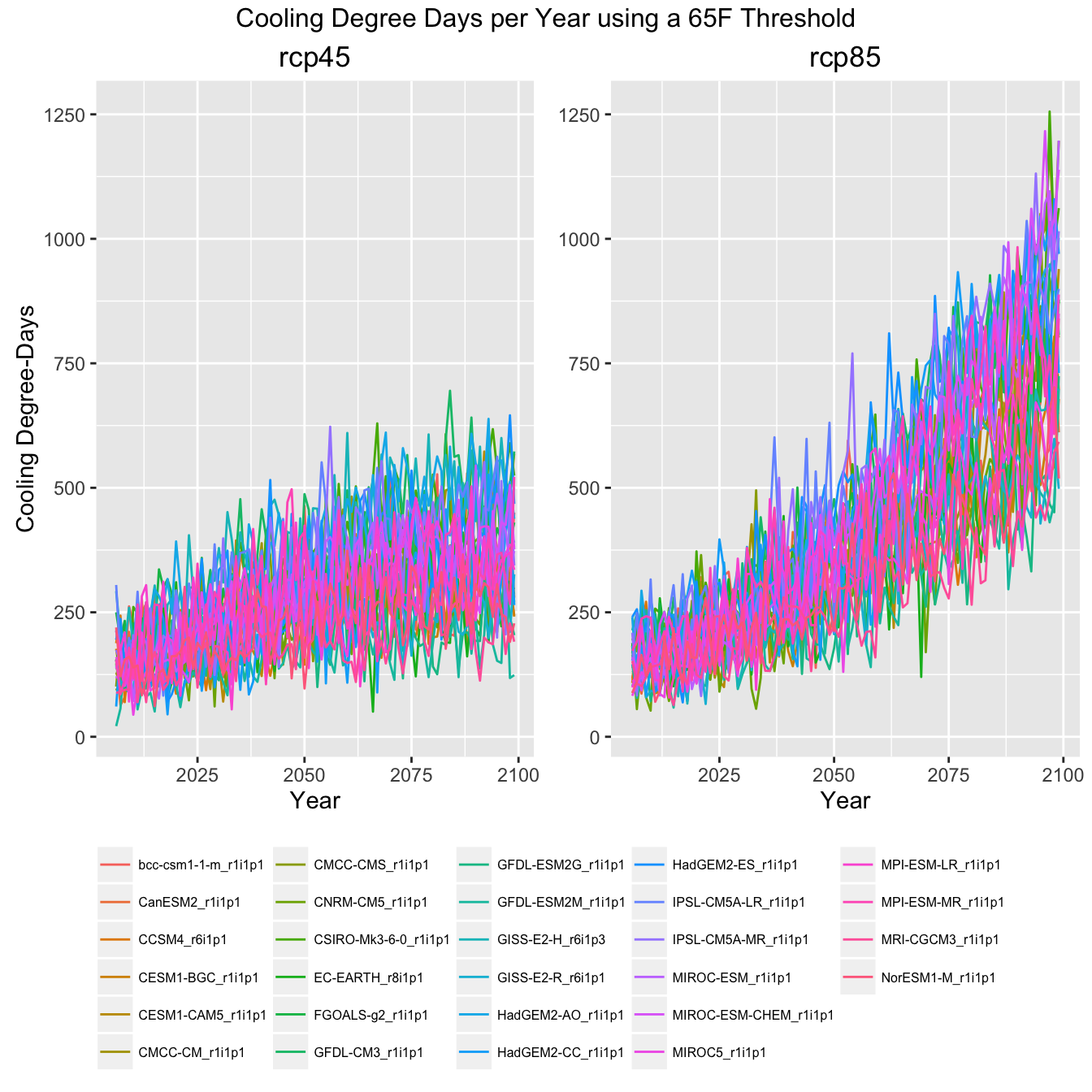
Climate Indicator Graph of All GCMs
Categories:
Related Posts
Visualizing Tropical Storm Colin Precipitation using geoknife
June 9, 2016
Tropical Storm Colin (TS Colin) made landfall on June 6 in western Florida. The storm moved up the east coast, hitting Georgia, South Carolina, and North Carolina.
The Hydro Network-Linked Data Index
November 2, 2020
Introduction updated 11-2-2020 after updates described here. The Hydro Network-Linked Data Index (NLDI) is a system that can index data to NHDPlus V2 catchments and offers a search service to discover indexed information.
Seasonal Analysis in EGRET
November 29, 2016
Introduction This document describes how to obtain seasonal information from the R package EGRET. For example, we might want to know the fraction of the load that takes place in the winter season (say that is December, January, and February).
Calculating Moving Averages and Historical Flow Quantiles
October 25, 2016
This post will show simple way to calculate moving averages, calculate historical-flow quantiles, and plot that information. The goal is to reproduce the graph at this link: PA Graph.
The case for reproducibility
October 6, 2016
Science is hard. Why make it harder? Scientists and researchers spend a lot of time on data preparation and analysis, and some of these analyses are quite computationally intensive.