
Formatting guidance for USGS Samples Data Tables
Tips and example R scripts for converting long-formatted data into wide tabular format
What's on this page
Recently, changes were made to the delivery format of USGS samples data (learn more here ). In this blog, we describe the impact to users and show an example of how to use R to convert WQX-formatted water quality results data to a tabular, or “wide” view.
Background
USGS modernized the way we deliver data from discrete field sampling events from a USGS-specific format to the internationally-recognized Water Quality Exchange (WQX) standard. As part of this transition, users have had to update their workflows to access the new sample data outputs. We’ve heard from many users that they would like the ability to create and view tables that are similar to tables that were previously available as an output from the NWIS ‘qw’ webpages. This blog post offers some suggestions for modifying data in the WQX format to a different tabular view.
What is a long or wide data table?
WQX data follow tidy principles , which are often easier to use in scripting language. With tidy data:
- Each variable has its own column
- Each observation has its own row
- Each value has its own cell
Converting WQX data into a different tabular output may be turning a “long” data table into a “wide” data table. Data coming from USGS endpoints in the WQX standard are in a long format. The long data format allows for delivery of result-specific metadata that scientists often seek and is commonly favored in data science. However, data in the long format look different than historic National Water Information System (NWIS) ‘qw’ tables. Most commonly, tables in NWIS ‘qw’ were able to be viewed by sampling activities occurring on the same date and time, which can create very wide tables if a particular sampling activity produced many results (a common occurrence for water quality samples). This table often ends up being much wider than a user can view on a single screen!
Both long and wide data formats are acceptable methods for delivering data and each has their own advantages. Long data tables are generally preferred when performing calculations and for aggregating data for statistical analyses. Wide data tables are generally good for quick review or interpretation: for example, a user can view changes in a set of measured properties over time.
Let’s illustrate using R, with an example snippet of a “long” table (Note: example is an excerpt from the dataRetrieval vignette called “Pivot Data”, available here
):
long <- tibble(site = c(rep("A", 4), rep("B", 4)),
day = c(rep(c(1, 1, 2, 2), 2)),
param = c(rep(c("Atrazine", "Metolachlor"), 4)),
value = c(0.1, 0.25, 0.13, 0.38,
0.14, 0.38, 0.15, 0.40))
#> site day param value
#> A 1 Atrazine 0.10
#> A 1 Metolachlor 0.25
#> A 2 Atrazine 0.13
#> A 2 Metolachlor 0.38
#> B 1 Atrazine 0.14
#> B 1 Metolachlor 0.38
#> B 2 Atrazine 0.15
#> B 2 Metolachlor 0.40
As the table shows, there is one measurement per row. A single column, param, lists each measured property (e.g. parameter), and measurements from the same location and sampling event are spread over multiple rows.
Here is a snippet of the exact same data in “wide” table format:
wide <- tidyr::pivot_wider(long,
names_from = param,
values_from = value)
#> site day Atrazine Metolachlor
#> A 1 0.10 0.25
#> A 2 0.13 0.38
#> B 1 0.14 0.38
#> B 2 0.15 0.40
The “wide” table has one row for all measurements for a particular location and sampling event, with each unique parameter having its own column. For samples with a lot of measurements, as is common for water quality samples, this can lead to a really wide table!
Example: A wide view of detection limit data
Here’s an example in R using the tidyverse ecosystem. Let’s say we want to view a table of all detection limit data for 2 phosphorus measured properties from 2 locations. Note that the results can represent distinct sampling events, so we need to keep track of metadata including sampling date and time, as well as activity type.
We can use the package dataRetrieval to access USGS discrete water quality data. Here we are accessing data from the USGS Samples web service
, but the same approach applies to any long-formatted data set, such as the legacy Water Quality Portal
or the new WQX3 web services.
library(dataRetrieval)
library(tidyverse)
sites <- c("USGS-04027000", "USGS-04063700")
characteristic_names <- c("Phosphorus as phosphorus, water, filtered",
"Orthophosphate as phosphorus, water, filtered" )
nutrient_data <- read_waterdata_samples(monitoringLocationIdentifier = sites,
characteristicUserSupplied = characteristic_names,
dataProfile = "basicphyschem")
The data comes back with dozens of columns (note that dataRetrieval creates some new columns for us, importantly one called Activity_StartDateTime that concatenates the Activity_StartDate and Activity_StartTime): let’s make this a little easier to handle by pulling out the ones we decide are important for our analysis. We’ll rename the columns so they are easier to read on the screen, however the rename is not necessary. Your own data may need many more columns!
nutrient_data_slim <- nutrient_data |>
# pick columns of interest and re-name
select(date = Activity_StartDateTime,
site = Location_Identifier,
param = USGSpcode,
activity_type = Activity_TypeCode,
cond = Result_ResultDetectionCondition,
val = Result_Measure,
det_va = DetectionLimit_MeasureA,
units = Result_MeasureUnit,
det_units = DetectionLimit_MeasureUnitA) |>
# update flagged result values
mutate(val = case_when(!is.na(cond) ~ det_va,
TRUE ~ val),
units = case_when(!is.na(cond) ~ det_units,
TRUE ~ units),
cond = case_when(!is.na(cond) ~ "<",
.default = "")) |>
# keep routine records
filter(!is.na(date),
activity_type == "Sample - Routine, regular") |>
# remove more columns
select(-det_units, -det_va, -activity_type)
#> date site param cond val units
#> 1971-10-06 17:25:00 USGS-04063700 00666 0.03 mg/L
#> 1977-10-18 16:00:00 USGS-04027000 00666 0.01 mg/L
#> 1977-11-08 22:30:00 USGS-04027000 00666 0.01 mg/L
#> 1977-12-06 20:00:00 USGS-04027000 00666 0.02 mg/L
#> 1978-01-04 20:30:00 USGS-04027000 00666 0.02 mg/L
#> 1979-11-21 14:15:00 USGS-04063700 00671 0.00 mg/L
For this analysis, each parameter needs individual detection conditions, values, units, and detection limits. Using the tidyr package, we can run the pivot_wider function and get a table with all the required columns.
library(tidyr)
nutrients_wide <- nutrient_data_slim |>
pivot_wider(names_from = c(param, units),
values_from = c(cond, val))
#> date site det_cond_00666_mg/L det_cond_00671_mg/L val_00666_mg/L val_00671_mg/L
#> 1971-10-06 17:25:00 USGS-04063700 NA 0.03 NA
#> 1977-10-18 16:00:00 USGS-04027000 NA 0.01 NA
#> 1977-11-08 22:30:00 USGS-04027000 NA 0.01 NA
#> 1977-12-06 20:00:00 USGS-04027000 NA 0.02 NA
#> 1978-01-04 20:30:00 USGS-04027000 NA 0.02 NA
#> 1979-11-21 14:15:00 USGS-04063700 NA NA 0
Many options exist to customize the appearance of these tabular outputs, including sorting by parameter.
Example: Which columns should I use to widen my dataset?
The previous example focuses on detection limit data, however a user could modify this to widen by other variables based on their specific needs and use cases. One decision users will need to make is how they want the table to be organized, including which variables to widen with and what metadata to retain in the final table.
Legacy NWIS ‘qw’ tables were commonly organized by the date and time of the sampling event; a very similar concept to this is the sampling activity. Users can manipulate data to be organized by sampling activity, thereby creating a much wider table while dropping supporting metadata. To make tables look more similar to legacy tables, users can also concatenate metadata fields.
In the next example, as part of our data quality checks we want to review all discrete sample data at one site for Water Year 2024. We applied the following processing steps before widening:
- Retain only routine samples by applying a filter on the field
Activity_TypeCode - Concatenate column names to include parameter information, specifically
USGSpcodeandCharacteristicUserSupplied(a.k.a. Observed Property ) - Concatenate
Result_MeasureandResult_MeasureUnits - Find and replace non-detect measurements with the combined values in
Result_ResultDetectionConditionandDetectionLimit_MeasureA.
For the widened data table, let’s separate results by status value, e.g. Provisional versus Accepted, so we can see which data still require final review.
# create site list
sites <- "USGS-04027000"
# access date
nutrient_data <- read_waterdata_samples(monitoringLocationIdentifier = sites,
activityStartDateLower = "2023-10-01",
activityStartDateUpper = "2024-09-30",
dataProfile = "basicphyschem")
# pre-process
nutrient_data_slim <- nutrient_data |>
select(date = Activity_StartDateTime,
site = Location_Identifier,
activity = Activity_ActivityIdentifier,
param = USGSpcode,
activity_type = Activity_TypeCode,
cond = Result_ResultDetectionCondition,
val = Result_Measure,
units = Result_MeasureUnit,
det_va = DetectionLimit_MeasureA,
det_units = DetectionLimit_MeasureUnitA,
ObsProp = Result_CharacteristicUserSupplied,
status = Result_MeasureStatusIdentifier) |>
mutate(val = case_when(!is.na(cond) ~ as.numeric(det_va),
TRUE ~ as.numeric(val)),
units = case_when(!is.na(cond) ~ det_units,
TRUE ~ units),
cond = case_when(!is.na(cond) ~ "<",
.default = ""),
headers = paste(status, param, ObsProp, sep = "_")) |> # concatenate fields for header names
mutate(val = paste(cond, val, units)) |>
filter(!is.na(date),
activity_type == "Sample - Routine, regular") |>
select(-det_va, -det_units, -cond, -units, -activity_type)
# now widen!
nutrients_wide <- nutrient_data_slim |>
pivot_wider(id_cols = c(site,
date,
activity),
names_from = headers,
values_from = c(val))
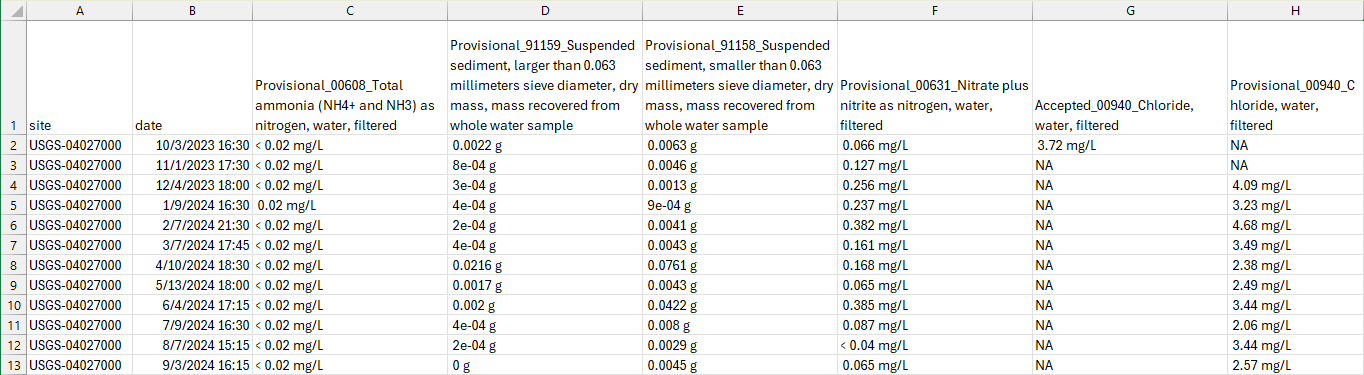
Screen capture of a wide-formatted data table resulting from the R code above and downloaded in .csv format. For brevity, a subset of columns are shown: the actual data set has more columns.
One important point to note in these examples—and really whenever you are transforming a long, metadata-rich data set from long to wide format—is that the resulting tables will have lost some metadata. That is why it is important for users to pre-process their data by performing quality assurance checks and filtering unwanted data and metadata fields before converting to a wide-formatted table.
Summary
This article provides just a couple of examples to help modify long WQX data into a wide data format using R. Tools also exist in Python’s pandas package, and Microsoft Excel has some interactive tools for widening data using the Pivot Table feature. We provide a (very limited!) set of resources below as a starting point and encourage users to explore beyond the basics provided here.
Helpful resources
- Useful video describing long and wide data formats
- Python
pandaspivot function documentation - Python
pandaspivot function example (statology.org ) - Microsoft Excel instructions on creating a pivot table
- Video demonstrating conversion between long and wide format with Excel’s Power Query
You can also contact us with questions or comments at wqx@epa.gov .
Categories:
Related Posts
Tutorial of dataRetrieval's newest features in R
November 26, 2025
This article will describe the R-package
dataRetrieval, which simplifies the process of finding and retrieving water from the U.S. Geological Survey (USGS) and other agencies. We have recently released a new version ofdataRetrievalto work with the modernized Water Data APIs . The new version ofdataRetrievalhas several benefits for new and existing users:Reproducible Data Science in R: Say the quiet part out loud with assertion tests
September 2, 2025

Overview
This blog post is part of the Reprodicuble data science in R series that works up from functional programming foundations through the use of the targets R package to create efficient, reproducible data workflows.
Duplicating Quarto elements with code templates to reduce copy and paste errors
May 20, 2025
Introduction

It is a common situation in data science and analysis: We want to create a series of figures, tables, or summary statistics for a set of data. Maybe we’re studying different species of irises or penguins or the current flow conditions for various streamgages (the example used below), and we want a different summary figure or table for each. One common approach is to write code for one set of the data, such as setting up the graphing parameters in a
ggplotdata visualization or calculating a series of statistics for a single species/streamgage. Then, once happy with that, copying and pasting the code for each entity, modifying the code slightly for each iteration.Reproducible Data Science in R: Flexible functions using tidy evaluation
December 17, 2024

Overview
This blog post is part of a series that works up from functional programming foundations through the use of the targets R package to create efficient, reproducible data workflows.
Reproducible Data Science in R: Iterate, don't duplicate
July 18, 2024

Overview
This blog post is part of a series that works up from functional programming foundations through the use of the targets R package to create efficient, reproducible data workflows.