
Duplicating Quarto elements with code templates to reduce copy and paste errors
Quarto provides easier-than-ever ways to create data-driven, reproducible documents. This blog demonstrates how to use custom code templates to easily replicate code chunks with a reproducible USGS streamgage example!
What's on this page
Introduction

It is a common situation in data science and analysis: We want to create a series of figures, tables, or summary statistics for a set of data. Maybe we’re studying different species of irises or penguins or the current flow conditions for various streamgages (the example used below), and we want a different summary figure or table for each. One common approach is to write code for one set of the data, such as setting up the graphing parameters in a ggplot data visualization or calculating a series of statistics for a single species/streamgage. Then, once happy with that, copying and pasting the code for each entity, modifying the code slightly for each iteration.
There are problems with this copy + paste + modify approach: It can be tedious and is error-prone. It’s difficult to do this for more than a handful of instances, and if we want to change something later, we’re faced with making sure all the changes are recreated in each chunk. Learn other ways to improve iteration in our previous blog post .
The goal with this blog is to provide a simpler way of creating a report or slideshow in markdown (either .Rmd or Quarto’s .qmd format) that is automated and relies on a template, making this type of process easier. I will first provide a simple example of the code to implement this approach. Then I will also demonstrate a couple more advanced examples specific to creating PowerPoint slides from Quarto code.
Iterating with the traditional approach
To begin, I will use streamflow data downloaded from our USGS dataRetrieval package, which is demonstrated in a previous blog
. In this scenario, I am trying to create a PowerPoint presentation with a graph that shows a monthly hydrograph for each of three streamgages. I create a new Quarto document, create a code chunk to make the hydrograph for the first gage and then copy + paste + modify that chunk for the other two gages. This is what that Quarto might look like:
---
title: "Streamgage Example"
format: pptx
---
```{r, echo=FALSE}
library(tidyverse)
# Data will be downloaded from dataRetrieval
library(dataRetrieval)
flow_ks <- readNWISdata(
# State Code
stateCd = "KS",
# Parameter Codes
parameterCd = c("00060"),
# Timeframe
startDate = "2024-02-15",
endDate = "2024-03-15",
# Daily values
service = "dv") |>
# Clean up the column names a bit
renameNWISColumns() |>
# Select the 3 focal gages
filter(site_no %in% c("07170500", "07172000", "07182260"))
```
## Streamgage 07170500 summary
```{r}
ggplot(data = flow_ks |> filter(site_no == "07170500"),
aes(x = dateTime, y = Flow)) +
geom_line() +
ggtitle("Gage 07170500") +
theme_minimal()
```
## Streamgage 07172000 summary
```{r}
ggplot(data = flow_ks |> filter(site_no == "07172000"),
aes(x = dateTime, y = Flow)) +
geom_line() +
ggtitle("Gage 07172000") +
theme_minimal()
```
## Streamgage 07182260 summary
```{r}
ggplot(data = flow_ks |> filter(site_no == "07182260"),
aes(x = dateTime, y = Flow)) +
geom_line() +
ggtitle("Gage 07182260") +
theme_minimal()
```
The final PowerPoint looks like this:
One strength to this “copy + paste + modify” approach is that it’s easy to implement, since we only slightly modify the same piece of code for each entity in our data set. A major weakness is that it’s difficult/tedious to generalize to more than a few entities, since this piece of code needs to be manually copied + pasted for each entity. In the next section, I will introduce a template-based approach that automates this process.
Iterating with the (better) template approach
The basic approach is to take advantage of the knitr
package’s knit_child()
function, which takes a child document or “template” and pastes a character string in the main document. Any R or markdown code we include in this template document will be treated as if we had written it in the main document. Here, I will keep the same structure of the parent Quarto document used in the previous section, which will have the YAML header that indicates I’m going to create a PowerPoint slide deck.
In the global header chunk of code, I will create a vector called gages containing the unique gage IDs and a wrapper function called child_function that will use knitr::knit_child(), the template slide layout called gage_example_child.qmd, and input data.
I can then use a for-loop (or purrr:map()
if you prefer) to iterate over the elements of the gages vector, inserting each gage ID into the gage_example_child.qmd template and pasting the resulting R code into the main document. See further below for the contents of the gage_example_child.qmd template.
Note that you do need to put the chunk argument
results="asis"for the Quarto markdown rendering engine to read the input child code as executable markdown and R code.
I then end the looping function with cat(unlist(out_slide), sep = " ") which helps the Quarto rendering engine recognize the text from the child function as executable.
This is what the new main quarto document looks like:
---
title: "Streamgage Example with template"
format: pptx
---
```{r, echo=FALSE}
library(tidyverse)
# Data will be downloaded from dataRetrieval
library(dataRetrieval)
# What are you looping over? Here, the focal gages
gages <- c("07170500", "07172000", "07182260")
# Data will be downloaded from dataRetrieval
library(dataRetrieval)
flow_ks <- readNWISdata(
# State Code
stateCd = "KS",
# Parameter Codes
parameterCd = c("00060"),
# Timeframe
startDate = "2024-02-15",
endDate = "2024-03-15",
# Daily values
service = "dv") |>
# Clean up the column names a bit
renameNWISColumns() |>
# Select the 3 focal gages
filter(site_no %in% gages)
# Function that reads in the template markdown
child_function <- function(this_gage){
knitr::knit_child("gage_example_child.qmd",
envir = environment(),
quiet = TRUE)
}
```
```{r, results="asis"}
for(ss in 1:length(gages)){
# Create slide content for the site
out_slide <- child_function(this_gage = gages[ss])
# Cat and unlist reads in the child function in and converts it to quarto code
cat(unlist(out_slide), sep = "\n")
}
```
The template child gage_example_child.qmd file is simple and does not include a YAML header. This is the entire document:
## Streamgage `r this_gage` summary
```{r}
library(ggplot2)
library(tidyverse)
ggplot(data = flow_ks |> filter(site_no == this_gage),
aes(x = dateTime, y = Flow)) +
geom_line() +
ggtitle(sprintf("Gage %s", this_gage)) +
theme_minimal()
```
Note that the gage ID used in the child_function() call is inserted into this code in place of this_gage.
Now, when you render the main Quarto document, you get the same set of slides as before:
The benefits of using the template approach
This is a very simplified example with only three gages, and it may not feel worth it to set up this template when you are only modifying three slides. However, one of the best benefits to this approach is that edits to the slides are easier. Instead of changing each gage’s chunk manually, you can just change the template once and all slides will get updated (see next two examples). Another benefit is that this approach easily expands to more than three data sets. For example, we would simply need to add to the gages character vector if we wanted hydrographs for additional gages. Anything that makes future you happy is a good thing to do!
The following sections show how you can add more features to the PowerPoint slides by adding to the template document. See the PowerPoint Quarto documentation for more tips and tricks.
Advanced Quarto -> PowerPoint Examples
1: Add columns and table to slides
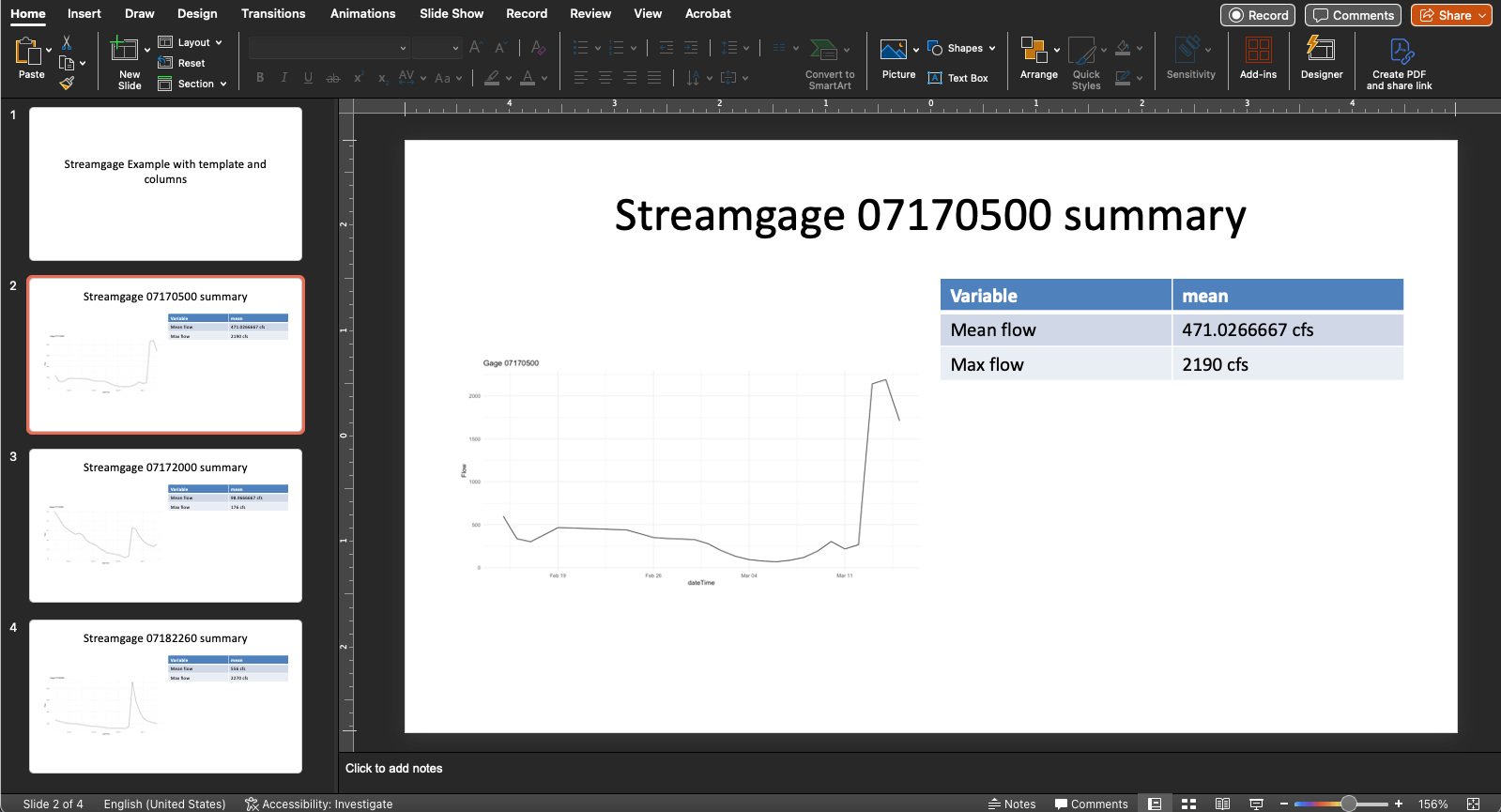
With the template format set up for each gage’s slide, it’s very easy to add in additional features to the PowerPoint by changing the template. Changing the code in the template will change all of the resulting PowerPoint slides. For example, the template code below shows how you can add columns to each slide
to make room for a summary table. Columns are added in Quarto markdown by first delineating a space to define columns with :::: columns (start) and :::: (end). Then, each column’s code will be placed in a new column beginning with ::: {.column} and ending with :::. This is the updated child item’s code to create two columns per slide. Note that the original “parent” markdown does not need to change at all!
## Streamgage `r this_gage` summary
:::: columns
::: {.column}
```{r}
library(tidyverse)
ggplot(data = flow_ks |> filter(site_no == this_gage),
aes(x = dateTime, y = Flow)) +
geom_line() +
ggtitle(sprintf("Gage %s", this_gage)) +
theme_minimal()
```
:::
::: {.column}
Variable | mean
----- | --
Mean flow | `r mean(flow_ks$Flow[flow_ks$site_no == this_gage])` cfs
Max flow | `r max(flow_ks$Flow[flow_ks$site_no == this_gage])` cfs
:::
::::
2: Add speaker notes
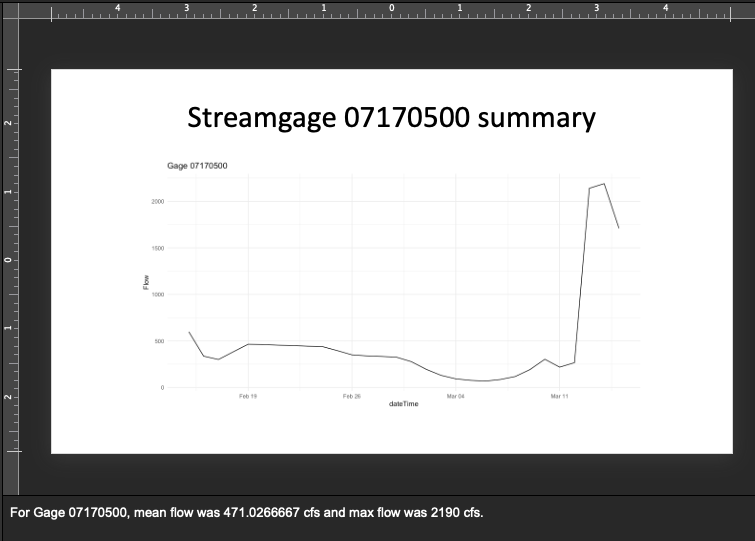
One more handy thing that you can do with the Quarto-generated PowerPoint slides is add in speaker notes
. Here, instead of being put into a table as in the prior example, the statistics for mean and max streamflow are added as speaker notes. In a Quarto presentation, the notes section begins with ::: notes and ends with :::. Again, with the template style, all we need to change is the template markdown document to change all of the slides in the final PowerPoint!
## Streamgage `r this_gage` summary
```{r}
library(ggplot2)
library(tidyverse)
ggplot(data = flow_ks |> filter(site_no == this_gage),
aes(x = dateTime, y = Flow)) +
geom_line() +
ggtitle(sprintf("Gage %s", this_gage)) +
theme_minimal()
```
::: notes
For Gage `r this_gage`, mean flow was `r mean(flow_ks$Flow[flow_ks$site_no == this_gage])` cfs and max flow was `r max(flow_ks$Flow[flow_ks$site_no == this_gage])` cfs.
:::
Conclusions
By applying a template markdown document as a “child” of your main “parent” Quarto document, you can easily create and modify a series of figures, tables, or slides. The example shared here is simple, but can work as a reproducible guide for your next Quarto project. I hope that using this type of child-parent template format will save your future self lots of headaches and time!
Categories:
Related Posts
Jazz up your ggplots!
July 21, 2023
At Vizlab , we make fun and accessible data visualizations to communicate USGS research and data. Upon taking a closer look at some of our visualizations, you may think:
Recreating the U.S. River Conditions animations in R
March 29, 2021
For the last few years, we have released quarterly animations of streamflow conditions at all active USGS streamflow sites . These visualizations use daily streamflow measurements pulled from the USGS National Water Information System (NWIS) to show how streamflow changes throughout the year and highlight the reasons behind some hydrologic patterns. Here, I walk through the steps to recreate a similar version in R.
Beyond Basic R - Mapping
August 16, 2018
Introduction
There are many different R packages for dealing with spatial data. The main distinctions between them involve the types of data they work with — raster or vector — and the sophistication of the analyses they can do. Raster data can be thought of as pixels, similar to an image, while vector data consists of points, lines, or polygons. Spatial data manipulation can be quite complex, but creating some basic plots can be done with just a few commands. In this post, we will show simple examples of raster and vector spatial data for plotting a watershed and gage locations, and link to some other more complex examples.
Exploring ggplot2 boxplots - Defining limits and adjusting style
August 10, 2018
Boxplots are often used to show data distributions, and
ggplot2is often used to visualize data. A question that comes up is what exactly do the box plots represent? Theggplot2box plots follow standard Tukey representations, and there are many references of this online and in standard statistical text books. The base R function to calculate the box plot limits isboxplot.stats. The help file for this function is very informative, but it’s often non-R users asking what exactly the plot means. Therefore, this post breaks down the calculations into (hopefully!) easy-to-follow chunks of code for you to make your own box plot legend if necessary. Some additional goals here are to create boxplots that come close to USGS style. Features in this post take advantage of enhancements toggplot2in version 3.0.0 or later.Beyond Basic R - Plotting with ggplot2 and Multiple Plots in One Figure
August 9, 2018
R can create almost any plot imaginable and as with most things in R if you don’t know where to start, try Google. The Introduction to R curriculum summarizes some of the most used plots, but cannot begin to expose people to the breadth of plot options that exist.There are existing resources that are great references for plotting in R: